Scaling up to 1 Million Requests per Minute: How Cloudsmith Delivers Extreme Performance
“Cloud-native isn't a label for the team at Cloudsmith and me; it’s why we can hit 700K requests per minute without waking anyone up. By leveraging multi-region deployment, built-in edge caching, and elastic scaling, Cloudsmith delivers a highly available ‘invisible in the right ways’ artifact management experience for teams of all sizes out of the box.”
— David González, Principal Engineer at Cloudsmith
Avoiding Chaos at Scale
CI/CD pipelines don’t wait. When traffic surges and your artifact platform can’t keep up, it’s not just a few slow requests: builds fail, deploys become backlogged, and engineers lose confidence. We’ve seen it all: 502s from overloaded infrastructure, minutes-long pulls, and pipelines grinding to a halt. That’s why we built Cloudsmith to scale by default; no one should have to firefight with their registry at 2 a.m. Our cloud-native capability is the difference between confidence and chaos.
Here at Cloudsmith, we recently validated our capacity to scale to 700K requests per minuteand beyond, thanks to the DNA of our genuinely cloud-native architecture. This article will share our thoughts on that high-volume test, how our architecture works, and why being cloud-native matters. We’ll also compare our model to so-called “cloud-hosted” solutions that rely on inferior approaches like manual replication or special edge nodes.
High-Volume Validation Without Advance Preparation
We regularly work with organizations that demand massive throughput from their artifact platforms. Enterprise customers migrating from legacy tools ask, "Can you handle our peak CI traffic?”. Some customers push over 12K requests per second, as in the case of this recent test, and that’s just business as usual.
These customer-run tests often combine short bursts (to simulate traffic spikes) with multi-hour soak sessions at high sustained rates, and we handle them without any special preparation from our operations team. Cloudsmith scales automatically across all regions throughout these testing cycles, delivering consistent performance.
We only ask for some notice before performance tests. This notice is so we can ensure that they are utilizing the tests to maximum effect and are “testing the right things” rather than needing it for preparation time or other biases that we try to avoid introducing. We’ll often suggest additional or alternative tests to demonstrate the power of Cloudsmith.
Speed at Scale with Edge Caching and Global Points of Presence
One of the most important (and often invisible) parts of Cloudsmith’s infrastructure is how we distribute packages globally. We think of it like this: no matter where in the world you’re working, downloading a package from Cloudsmith should feel like you’re pulling it from a machine in the next room.
To make that possible, we built the Package Distribution Network (PDN), a cloud-native evolution of the traditional content delivery network, purpose-built for artifacts. Under the hood, it leverages hundreds of fully managed Points of Presence (PoPs) distributed across the cloud. These edge locations bring packages and metadata physically closer to your developers and your CI runners.
The result? Local-rate latency, anywhere in the world. Faster builds. Happier teams.
Built-In Resilience and Custom Storage Regions
Because this is baked into the platform, there’s nothing to configure: no manual replication, no edge node setup, and no high-availability add-ons. Everything is automatic, including failover. If there’s an issue in one part of the network, we route around it, and the end user never notices. Valid packages continue to flow from the nearest healthy location.
Some customers go a step further, asking for things like custom storage regions and connectivity, whether for compliance, performance, or proximity. That’s also built-in. You can pin a repository to a specific country or region while benefiting from global distribution.
So yes, it is invisible infrastructure: real-time global delivery built for speed and resilience without anyone needing to lift a finger. Because artifact management isn’t just about what you store, it’s also about how fast and reliably you can get it to where it needs to be.
How Cloudsmith Scales Automatically Under Sudden Load
David González, a Principal Engineer, held the infrastructure pager for these tests, and here’s that bottom line again: we did nothing special to prepare. In this particular instance, he was notified that the test was going to happen, and being curious, he followed along by watching the wealth of observability capabilities we had built into our platform. If you’ve met many engineers, you’ll know that many of them subscribe to the so-called church of graphs. We're the same.
What we didn’t need to do during the test:
• No manual scaling out • No manual config • No edge node deployment • No late-night engineer scramble
We're always curious to see how tests are handled in action, knowing that our platform has been designed for horizontal scale since day one. We distribute workloads across cloud-managed services for storage, data, and global caching. Each layer scales itself, so there’s no need for frantic provisioning. It’s addictive to watch the system manage the load: scaling on demand, adapting to the ebb and flow of traffic, and never needing human intervention.
Edge Routing, Load Balancing, and Stateless Scaling
Handling over 700,000 requests per minute is not just about having capacity. It is about structuring the system so each component can absorb load, isolate failure, and stay fast under pressure.
At the entry point, everything starts at the edge. We use hundreds of global CloudFront points of presence, but layer them in our custom at-edge logic. That includes more innovative request routing, artifact-specific authentication, authorization, and targeted caching strategies. We handle portions of decision-making and routing at the edge before a request touches our core services. This reduces load, tightens latency, and improves performance for consuming clients no matter where they are.
When a request cannot be fulfilled at the edge, it is passed upstream. The application balances load across multiple regions globally, and application load balancers operate in various availability zones regionally; these are routed by latency and fault-tolerant balancing. These feed into a fleet of reverse proxies and web application containers deployed across AZs for redundancy and concurrency. Each component is independently stateless, so scaling and error handling are straightforward and fast.
Scaling Workloads and Separating Read/Write Operations
Internally, we use various computing models, including ECS with managed Fargate and various managed services. This gives us elasticity with less operational complexity, especially for background task workers that respond to load in bursts. Some workloads are CPU-heavy, others are network-intensive, and we can scale them independently based on demand profiles.
Data access is split, too. Write operations go to the primary database, while reads are distributed across replicas, typically in the same regions as the application servers. This separation of reads and writes avoids contention and gives us flexibility in tuning read-heavy endpoints like index, artifacts, and metadata serving. Traffic for different parts of the application is served separately.
Asynchronous Upload Processing and Cascaded Scaling
The pattern changes for uploads. The frontend API validates the request and returns quickly while the artifact is processed asynchronously. Our sync-to-async handoff is queue-based and uses RabbitMQ and Celery, with a pinch of SQS for different types of work. The key is ensuring that handoff is lightning fast. Many workers pick up tasks like scanning, syncing, or triggering webhooks, which are distributed, plus scale and operate independently across services and regions.
This layered model means scaling is not a single action. It is a cascade. Requests are handled locally. If not, they are distributed intelligently. Reads go to replicas. Writes are isolated. Processing is offloaded. And every stage has horizontal elasticity built in.
The result is a platform that tolerates high load and absorbs it gracefully. We engineered each part to scale with intent, not because we engineered for one specific spike.
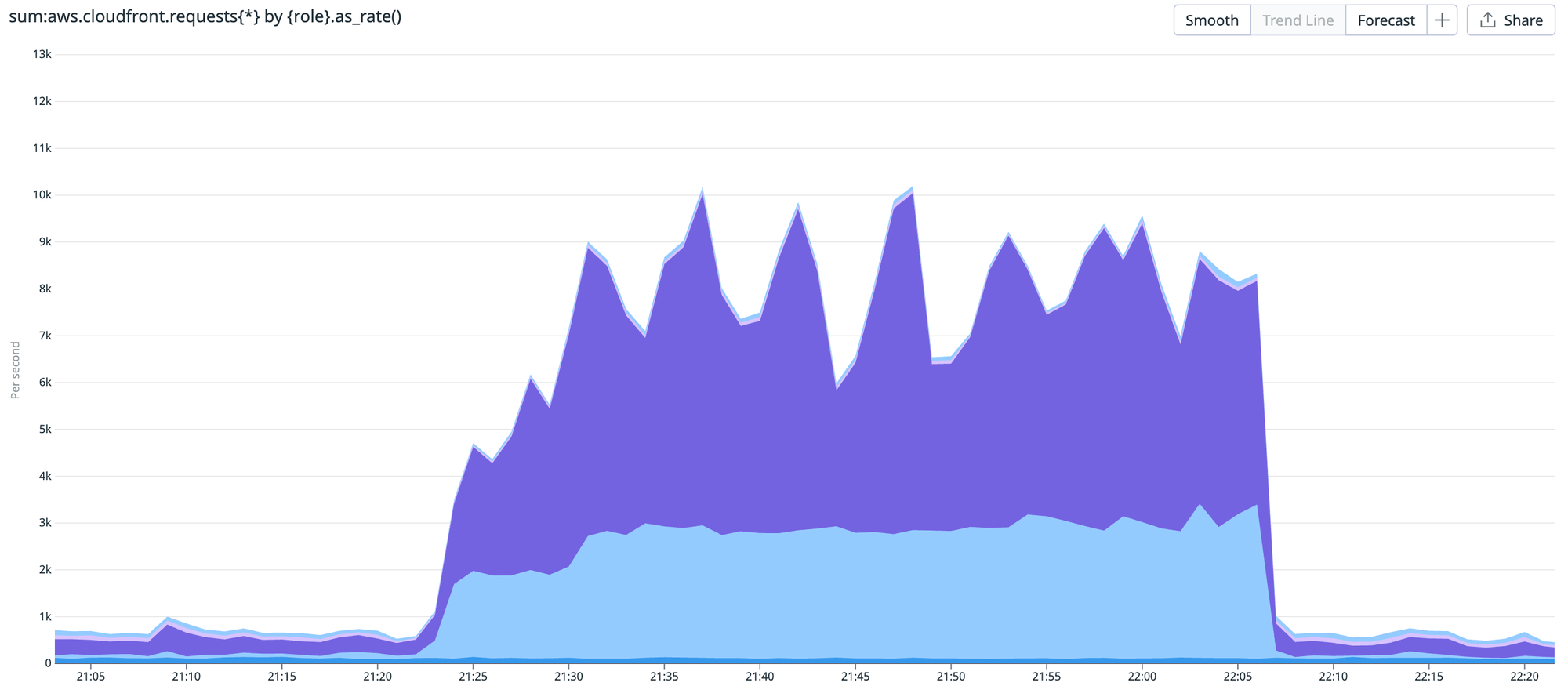
This graph shows CDN requests per second by role. Pale blue represents download requests, and purple is API requests.
Monitoring Automation at Scale and Knowing When to Step In
Of course, there’s always a practical limit to what it can do automatically, though it is far more than you might imagine. Examples include soft limits within the cloud provider or outlier instances where we encounter new and novel scenarios.
These are situations in which we ensure the quality of service and monitor for issues. In practice, we haven’t hit an absolute upper ceiling yet, and we work closely with our providers to ensure we don’t.
If anything goes wrong, the system pages us automatically. But we rarely need to intervene because that’s cloud-native in action.
In rare cases, we do step in, and that’s where the value of a fully managed service shines. Customers don’t just choose Cloudsmith for artifact management or software supply chain security; they buy Cloudsmith for the team behind it. That’s what they’re buying in reality, and why it’s “more than just bits and bytes.” It is made with love, because we want you to love it. We, as a team, are great to work with because we want you to love us. Software and service.
No Limits: Dynamic Scaling by Design
We often say that if we were on-prem, we’d be stuck with whatever hardware was on the floor. Because Cloudsmith was designed from day one as cloud-native infrastructure, we don’t just “run in the cloud”; we dynamically adapt, without human intervention, to whatever scale our customers demand. There’s no upper limit withdynamic scaling by design.
We designed it this way from the beginning, not by accident, but by questioning every “standard” pattern we saw in legacy systems. Did we want a big central cluster with manual failover? No. Did we want static auto-scaling groups that needed tuning per region? Also no. Instead, we leaned into platform-native primitives: distributed queues, serverless orchestration, container elasticity, and, importantly, the idea that no node should matter.
That design thinking shaped everything we built. And it’s why, to this day, our scaling story isn’t a hero story; it’s a systems story: quiet, automatic, reliable.
Legacy, on-prem solutions often require substantial up-front investments in hardware. Even “cloud-hosted” versions frequently rely on pre-sized compute clusters that require manual scaling or reconfiguration. By contrast, because we’re cloud-native, each layer, whether network, compute, storage, or caching, can expand on demand when requests spike. It’s the difference between a system that quietly scales vs. one that triggers a 3 a.m. scramble for you to deal with.
Designed for the Toughest Enterprise Demands
Enterprise scale isn’t just about high request volumes; it’s about managingcomplexity at every layer. You’ve got massive engineering teams, aggressive automation, exploding dependency trees, compliance obligations across regions, and AI generating more code than most humans can audit in a lifetime.
“But this is about more than just scale. We believe in a fundamentally important mission: securing the world of software by redefining software supply chains. Secure software delivery has become a critical capability; every company globally relies on it.”
— Lee Skillen, Chief Technology Officer at Cloudsmith
At Cloudsmith, we’ve seen what happens when infrastructure isn’t built for this kind of pressure: manual scaling, delays, missed release windows, and security incidents from misconfigured distribution; it's the often hidden cost of platforms that rely on a dedicated ops team for management and tuning. So, we designed a platform that thrives on chaos and never slows down when it matters most.
We've seen some of the world’s largest enterprises trust Cloudsmith to deliver artifacts for thousands of developers across the globe every hour of the day, and it is easy to see why: it’s because of that multi-tenant SaaS approach and any performance or resilience improvements made for one enterprise, ripple out to all, startups included.
There’s no “special enterprise-only tier” for fundamental platform capability, no hidden high-availability modules or add-ons, and no need for bespoke edge deployments. Have we said it already? Probably. But it’s worth repeating: it just works… by design.
Global Presence with Built-In Redundancy
One thing we always find fascinating is how failover feels… boring. And that’s by design. When an issue hits a particular region, which does happen because networks are messy, it’s already too late to start reacting. Instead, we route around it instantly. It’s surreal to watch: customers continue pulling artifacts, CI jobs don’t pause, and the problematic regions, zones, or nodes are being isolated and replaced behind the scenes.
“We run in multiple geographic locations worldwide, including North America, Europe, and Asia-Pacific. Our servers auto-scale and have full redundancy for failover, so if something goes down, capacity’s already waiting, and even if entire regions have an issue, traffic routes around. Our customers rarely notice, and we aim for zero downtime.”
— Paddy Carey, Principal Engineer at Cloudsmith
That worldwide presence and "cloud in our DNA" is part of what makes us genuinely cloud-native. Many so-called "cloud solutions" are on-premises architectures repackaged into virtualized environments, and even when they're not, if you have to think about how it is run, then it is leaking details to you that turn you into the ops team for artifact management. Cloudsmith? We don’t lift and shift. We scale and thrive. It’s boring, in all the precisely right ways, just as critical infrastructure should be.
Leveraging the Cloud as It Should Be
Not all cloud-based systems are created equal. While many tools claim to be "cloud-native," the reality spans a spectrum, from basic cloud hosting to entirely abstracted, self-managing platforms. Understanding where a system falls on that spectrum helps explain the experience it delivers under load.
Cloud-Hosted: These platforms are typically adapted from on-premises software. They are lifted into the cloud, often running within virtual machines or managed clusters, but maintain much of the original architecture. Scaling is usually manual or semi-automated, replication may require explicit setup, and high availability is an add-on or separate configuration. While these systems can operate in the cloud, they expose significant infrastructure details and operational responsibility to the customer.
Partially Cloud-Native: Some platforms go further. They adopt containerization, integrate with managed services, and automate parts of the scaling process. These systems may offer better elasticity and availability than purely cloud-hosted solutions, but still surface infrastructure abstractions to the user. Customers may need to consider configuring edge nodes, setting up failover regions, replication, and the latency of artifacts between locations. While these systems leverage cloud capabilities, they don’t entirely hide the complexity behind the scenes; i.e., it's still a leaky abstraction layer.
Genuinely Cloud-Native: Built from the ground up for the cloud. They are designed around declarative infrastructure, service abstraction, stateless scaling, and resilience by default, and they cooperate with a product designed for them. These platforms aim to eliminate the user's operational burden: scaling is implicit, replication is automatic, and infrastructure becomes effectively invisible. Users don’t manage clusters or capacity; they interact with a service that adapts dynamically to load, failure, and geography.
Why does it matter? The more cloud-native a system is, the less the user must understand or manage its underlying implementation. This doesn’t just improve performance at scale; it also reduces operational overhead, increases reliability, and allows teams to focus on delivering software, not managing infrastructure or having to choose a package pre-emptively that suits their geographic needs.
“The DNA of Cloudsmith is built on three deceptively simple things: simplicity in design, security by default, and being genuinely cloud-native. We heard the same frustrations from developers, security teams, and enterprises from the beginning: their tools were challenging to manage, painfully complex, and incapable of scaling to their demands.”
— Lee Skillen, Chief Technology Officer at Cloudsmith
Your team shouldn’t have to consider scaling, failover, or geographic location. With Cloudsmith and our genuinely cloud-native approach, they don’t.
The Outcome: “It just worked.”
Recalling that recent test, what was the outcome, anyway? Even with 700K requests per minute surges arriving at a distributed scale, the platform scaled out, distributing the load across regions and availability zones, and carried on its daily life. No other customers felt a thing: builds, pulls, and pipelines all carried on like usual. It’s all a testament to how authentic cloud-native design copes with high-scale demands. No heroics are required.
Why It Matters for Your Team
Even if you don’t have worldwide scaling requirements today, going cloud-native still offers immediate benefits:
Confidence for Growth: If your artifact or container image demands a spike, Cloudsmith scales automatically, with no reconfiguration or new licensing.
Protection from Surprises: We’ve seen customers caught out by the hidden ceilings in the legacy cloud-hosted tools with scaling limits they didn’t even know existed until things broke.
Everyday Speed: A platform designed for ultra-high traffic delivers faster artifact pulls, quicker builds, and minimal CI wait time, day in and day out.
No Extra Steps: No manual replication or confusion about which nodes are updated. Our architecture handles global distribution, letting you focus on development.
Cloud-native isn't a label for the team at Cloudsmith and me; it’s why we can hit 700K requests per minute without waking anyone up. By leveraging multi-region deployment, built-in edge caching, and elastic scaling, Cloudsmith delivers a highly available “invisible in the right ways” artifact management experience for teams of all sizes out of the box.
Built for Scale. Proven at Scale.
We’ve seen tests hit us at hundreds of thousands of requests per minute, sometimes with no warning. And every single time, we think the same thing: this is what infrastructure should feel like.Invisible. Reliable. Unsurprising. Cloudsmith isn’t cloud-native by accident; it’s cloud-native by design. And when the traffic hits, it just works.
Still stuck managing replication add-ons, high availability setups, or surprise downtime? It doesn’t have to be this way. Ditch the complexity and let Cloudsmith show you what actual cloud-native artifact management looks like. Ready to test your scale? Let’s talk.
Apache Maven is a popular and widely-used open-source build automation and project management tool primarily designed for Java projects.
We're excited to announce a major enhancement to our Maven rep…
April 2025 has brought some important news in the world of open source and software supply chain security: Fedora has announced a change proposal to make 99% of its package builds reproducible in its…
Kubernetes 1.33 is right around the corner, and there are quite a lot of changes to unpack! Removing enhancements with the status of “Deferred” or “Removed from Milestone” we have 64 Enhancements in a…
KubeCon London 2025 showed a cloud-native ecosystem shifting from fragmentation to unification of policy, security, observability, and artifact management…
SLSA (Supply-chain Levels for Software Artifacts, pronounced ‘salsa’) is a progressive, industry-backed software security framework that safeguards software integrity throughout the development and de…
Cloudsmith’s Enterprise Policy Management (EPM) now supports the Exploit Prediction Scoring System (EPSS), a data-driven metric designed to estimate the probability of a software vulnerability being e…